
You can import the blocks presented here as a project or download them as a library to import into your projects.
This chapter of the guide includes many interactive elements that are known to run well in the Chrome or Edge browser. See the troubleshooting guide for how to deal with problems encountered.
AI programs can do many things with text. These include
While computers can deal with text as strings of characters, a technique called word embedding works by converting words into a long list of numbers. These numbers can either be created by humans where each number has a meaning such as 'minimum size', 'maximum size' or 'average life expectancy'. Most AI programs instead use numbers created by machine learning (see the previous chapter and the next chapter). The numbers are created by training machine learning models on billions of words (e.g. all Wikipedia pages in a given language). People don't understand what the numbers mean but similar words have similar numbers and unrelated words have very different numbers. Each number measures a 'feature' of the word but what that feature is is a mystery.
The word embeddings used in this chapter were created by researchers at Facebook. They trained their machine learning models on 157 different languages on all Wikipedia articles in each language. Even though that was about a billion words each that wasn't enough, so they also trained their models on tens of billions more words found by crawling the web. They created tables for each language of at least a million different words. The blocks described here provide the 20,000 most common words for 15 languages (Chinese, English, Finnish, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Lithuanian, Portuguese, Sinhalese, Spanish, and Swedish). (Larger tables and more languages can be added. Send requests to toontalk@gmail.com.)
We have created Snap! blocks for exploring how word embeddings can be used to find similar words, words which are between other words, and most surprisingly solve word analogy problems. The features of word block will report a list of 300 numbers. If the language field is left empty, the default language will be used. You can think of the numbers as placing the word in a 300-dimensional space. The numbers were adjusted so all 20,000 words fit inside a 300-dimensional hypersphere with a radius of 1. There are databases with word embeddings for one million words but loading and searching such a large data set would be very slow. The features of word block is based upon the most frequently occurring 20,000 entries that are lower case (no proper nouns) and contain only letters (no punctuation or digits).
A program can search through all the words to find the word that is closest to a list of numbers. The closest word to reporter block does this.
Click to read an advanced topic
There are two common ways of measuring distance in a high-dimensional space. One is Euclidean distance which is a generalisation of how distance is computed in 2 and 3 dimensional space. The idea is to take the sum of the squares of the differences along each of the 300 dimensions and then report the square root of that. The other measure is called cosine similarity. Both work pretty well in the full-featured version of the closest word to reporter that lets you choose which to use. While they usually agree sometimes small differences can be observed. For example, the third closest word to "dog" can be "canine" or "puppy" depending on the measure. The default is cosine similarity because researchers have found it works a little better in high-dimensional spaces. Using the acos of block on the cosine similarity reporter produces the angle between the inputs which is easier to understand.
You can take two words and average their features by adding together corresponding numbers and dividing the result by 2. You can then use the closest word to reporter to find the word closest to the average.
Try averaging more than two words. And see what word is the closest to somewhere between two words other than the halfway point.
One of the most surprising things about word embeddings is that with the right formula one can solve word analogy problems. For example, "man is to woman as king is to what?" can be expressed as "king+(woman-man)=x".
Note that "king is to man as woman is to what?" can be expressed as "woman+(king-man)=x". And "king+(woman-man)=x" and "woman+(king-man)=x" are equivalent yet they solve different word analogy problems! This use of word embeddings works for grammatical analogies as well. Try solving "slow is to slower as fast is to what?". You might need to add 'fast' as an exception.
We have published some papers on using word embeddings. See our publications.
Note that for word analogies of the form A is to B as C is to D that the distance between A-B to C-D is much less than if A, B, C, and D were just words chosen at random. One could search through a list of words by choosing four words and measuring the distance between differences between pairs of words. If one only keeps those where the distance is small one may discover new word analogy puzzles. However, if one did this by searching through all 20,000 words then 3,998,800,199,970,000 combinations would have to be considered. Here is a project that enables one to search through a smaller set.
If you were to use the closest word to reporter to sort all the words by distance to a list of features, it would take about a full day since it will have to call the reporter 20,000 times. Instead we provide the closest words to reporter (notice the plural) that does it all at once in less than a second if the device has a GPU (except the first time it is called it may take several seconds). Optionally it can also report the distances as cosines.
While one rarely needs all 20,000 words it might be interesting to compare two words by seeing how many of the nearest 100 or 500 words of each are in common. Think up other uses for this reporter.
The features closest to list of features block reports which features are closest to a given feature list. It reports a list of all the listed features sorted by their distance to the given features. The cosine similarity is also reported. This block works well with word, sentence, or image embeddings. Or a data table as illustrated below. Note that the values should be in similar ranges. (Weights are given as hundreds of kilograms for this reason.)
One can compute sentence embeddings by averaging all the words in a sentence. There is, however, a much better way that uses models that were trained to address sentence-level tasks. The Universal Sentence Encoder is one such model that is available in the browser. The reporters get features of sentence and get features of sentences use this the Universal Sentence Encoder to produce 512 numbers for any sentence. (Really any sequence of words, it needn't be a grammatical sentence.)
It can be used to measure how similar two sentences are.
Consider
A. How are you?
B. How old are you?
C. What is your age?
A and B have many words in common but it is B and C that have similar meanings.
The get sentence features block accepts multi-word texts and reports a list of 512 numbers. To compare sentences we use cosine similarity that usually works better than Euclidean distance. Using arc cosine converts the cosine similarity to an angle for clarity.
The idea of using sentence embeddings to determine which sentence is closer to another sentence can be the basis of a game.
Sentence encodings can be used for more than comparing sentences. Combined with deep learning models (see the chapter on creating, training, and using machine learning models) they can be used to train a system to detect sentiment, emotions, topics, and more.
A full screen version of this program can be found here. The machine learning model used was trained in this project.
An alternative to the features of sentence block is one that uses a small version of GPT-3 from OpenAI. This service provides embeddings of 1536 numbers and is presumably of much higher quality. An API key from OpenAI is required. New users get an $18 free credit and the service is very inexpensive (one US dollar will cover the generation of embeddings for over a million words).
One use of sentence embeddings is information retrieval. Consider the task of searching the Snap! manual or this AI programming guide. String matching cannot take into account synonyms, different ways of saying the same thing, or different spelling conventions. In this sample search project sentence embeddings are used to compare the user's query with sentence fragments from the manual and guide. By relying upon the features closest to list of features block the closest fragments are found very quickly. The embeddings of all the fragments have been pre-computed so only the embedding of the user's query is needed. Once the closest fragments have been computed we can fall back upon string search since the fragments were derived from the document being searched.
One can use this AI-augmented search while working with Snap! by downloading and then importing either AI programming guide search or Snap! manual search. They work similarly and have similar interfaces. The results tend to be better if the query is a grammatical phrase and not a question.
The programming guide supports these keyboard commands:
The Snap! manual supports these keyboard commands:
Both the manual and guide search can be imported into the same project. But don't have both listening to your speech at the same time. When you no longer need this assistance just delete the imported sprite.
It would be nice to visualize the 300 numbers associated with a word. One way is to draw a succession of vertical lines, one for each feature.
A full screen version of this program can be found here. See if you can create other ways of visualizing embeddings. For example, to compare two embeddings perhaps the visualizations should be interleaved.
No one can visualize 300-dimensional space. There are techniques for giving an impression of the relationships between very high-dimensional points by mapping the points to two or three dimensions. We use a technique called t-SNE. It can be understood as a physics simulation where all points in crowded areas repel each other and all points are attracted to those with a small distance away (in high-dimensional space). This data projector displays all 20,000 English words in two or three dimensions using either t-SNE, PCA (principal component analysis), or UMAP. You can also use the projector to see the word embeddings of these languages: German, Greek, Spanish, French, Finnish, Hindi, Indonesian, Italian, Japanese, Lithuanian, Portuguese, Sinhalese, Swedish, and Chinese.
Note that it takes several hundred iterations of t-SNE before it settles down on a good mapping from 300 dimensions. You can also search for words and their neighbors and create bookmarks. The above links launch the projector with a bookmark showing t-SNE and highlighting the hundred words closes to 'dog'.
Here is a program that displays 50 random words at the location generated by t-SNE.
The blocks features of sentence and features of sentences can turn sentences into points in 512 dimensional space. Learn more here. While we can't visualize this space there are techniques for mapping these points into 2 or 3 dimensions that, while approximate, are often insightful. The TensorFlow Projector implements several such techniques in a web page. The projector needs two files: one with the sentence embeddings (i.e. location in the 512D space) and the other associating the text of the sentence with the embedding.
The <sentences> to TSV block reports the contents of the embeddings file and the <sentences> to TSV metadata block reports the contents of the metadata file. These blocks and a trivial example of their use can be found in the generate projector files project. Once these blocks have been run and the results exported as TSV files you can launch the TensorFlow Projector and click the Load button to load your files into the projector.
An example of using these blocks is this application of the TensorFlow Projector to the sentences in the Snap! manual. After exploring it we suggest you click on the APL bookmark to see one use this projection.
What would happen if you took, for example, the features of the English word 'dog' and
asked for the closest word in, say, French?
Try this with different source and target languages and different words.
Compare it with Google Translate.
Tip: it is easy to copy and paste words that your keyboard can't type from the Google Translate page.
Or you can use the input method editor
supported by the operating system of your device.
Supported languages are Chinese, English, Finnish, French, German, Greek, Hindi, Indonesian, Italian,
Japanese, Lithuanian, Portuguese, Sinhalese, Spanish, and Swedish.
Note that this version of closest word to has the choice of how one measures the distance between two vectors. Euclidean distance is the familiar 2D distance measure. Cosine similarity is similar but preferred by experts. See if it makes a difference in which words are closest to the untranslated word.
It is possible to add word embeddings for more languages. The process is documented here.
The following game picks a random word and gives the player warmer or colder feedback as the player makes guesses. This does so by comparing the distance to the secret word with the previous distance. It uses the location of ... reporter block to display your guesses. The game is very hard! There are many ways to make the game better. See if you can!
Natural language processing researchers have been training models to address sentence-level tasks such as question answering. They have Sesame Street names such as Elmo, Bert, and Ernie. Bert (really BERT which stands for Bidirectional Encoder Representations from Transformers) has been made available to browsers.
BERT is used in the implementation of the get up to 5 answers to question and answer question ... using this passage blocks. Given a passage of text (typically a page or less) they can answer questions about the contents. The get up to 5 answers to question block reports a list whose elements are lists of answers and a score indicating how confident the model is. An easy way to import a passage into Snap! is to drag a file that contains the plain text onto the script area.
GPT-3 is a neural network model that is capable of generating text in response to a prompt. The impressive thing is how often the generated text is very appropriate whether it is answering questions, fixing the grammar of a sentence, summarizing text, or following instructions. GPT-3 was trained on hundreds of billions of words from web pages and books. Surprisingly, the "only" thing it learns is to predict the next word (or token that is sometimes a part of a word). People call models like this "language models".
You can access GPT-3 from Snap! using the
complete
AI21 Studios has released a model similar to GPT-3 called Jurassic 1 as has Cohere.
The complete
GPT-3, Jurassic 1, or Cohere Gopher is a sample program that tries to hold a conversation using GPT-3, Jurassic 1, or Cohere. It uses speech recognition to listen to what you say. What you say is added to a prompt that tries to get GPT-3 to be a good conversationalist by describing the situation and giving it several conversational exchanges. It avoids the problem that as the conversation goes on the prompt gets too long for GPT-3 by truncating it while keeping the context description. Read Conversations with and between personas using language models to learn more.
The project supports several "personas". Gopher is an attempt at a friendly general conversationalist. El is prompted to pretend to be an elephant so one can ask her questions like "What is your favorite food?" or "Do you like jogging?". Eve pretends to be Mount Everest. Ask her questions like "What do you weigh?" or "How can I come visit you?". Charles is a simple simulation of Charles Darwin. Ask him about his life, evolution, or his books. Contrarian likes to argue while Curiosity is very inquisitive. These different personas are running the same script. The only difference is the introductory text and initial sample conversation. They can even talk among themselves!
Note that this project also illustrates how one can make a completely speech oriented interface. Other than the communication of your API key everything uses speech input and output. This is particularly useful when the project is run on a smartphone. Look at the script to see how it works.
Debate is a sample program that uses a language model from OpenAI, AI21 Studios, or Cohere to generate transcripts of a virtual debate on any topic. Read this post to learn more.
Turtle command generator is a sample program that uses GPT-3 to control the motion of a sprite. It works by getting GPT-3 to produce Logo turtle commands in response to spoken or typed instructions. Those commands are then converted to Snap! blocks. Read this post to learn more.
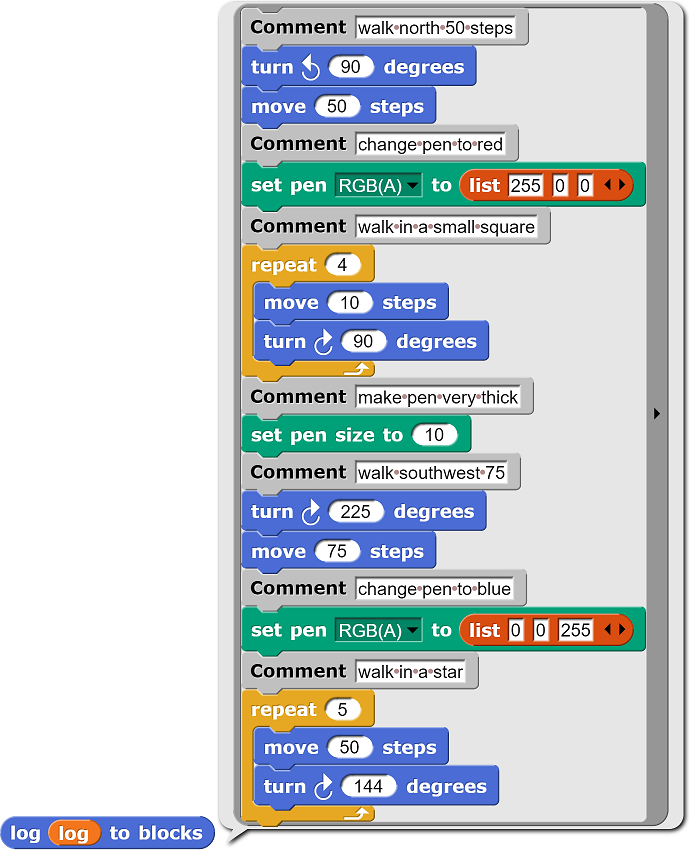
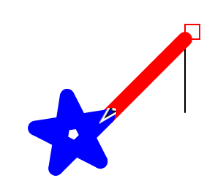
You can stop the project and run the log to blocks command to convert the history of your interaction into Snap! blocks. For example,
The Ask DALLE-2 to create ... costumes ... block can be used to generate costumes. With an API key from OpenAI one can use this block to generate costumes (at a cost of 2 US cents each or less). Your costume description can include medium (watercolor, photo, stainglass, oil painting, etc.), style (like Simpsons, Studio Ghibli, Rembrandt, Picasso, Cezanne, etc.), lighting, viewpoint, etc. Learn more about DALL-E-2 here.
This DALL-E-2 demo project asks for a description and creates two costumes, adds them to the sprite, and then fades in and out between them. It also demonstrates how to replace a color (white in this case) with transparency.
The Create a costume described as ... block relies upon the open-source Stable Diffusion text-to-image model. Anyone with a Google account can use Colab to run a server needed to run the block. See this Stable Diffusion Colab guide for details.
The Ask ... to create a costume described as ... block can use either the Stable Diffusion text-to-image model or DALLE-2 to generate images.
The Ask DALLE-2 to create ... costumes as variants of costume ... block can be used to make a variant of a costume. The width and height of the costume must be the same.
The Ask DALLE-2 to create ... costumes as edits of costume ... block can be used to edit a costume. The width and height of the costume and the "mask" costume must be the same. The "mask costume" should have transparent pixels that will be replaced depending what prompt is given.
This sample project combines DALL-E variants and editing blocks with the computer vision segmentation block. The project takes a photo of a person, creates a variant, uses segmentation to create a background mask, and DALL-E editing to change the background in accord with the inputed prompt.
Hugging Face provides access to over 15,000 neural network models. Free API keys are available that are limited to 30,000 input characters per month when communicating with text-based models. Additional input costs $10 per million characters. See Hugging Face pricing.
This Hugging Face project contains examples of using Hugging Face models to
Codenames is an award-winning board game. Each team has a spymaster who provides a single word clue to his or her teammates. The teammates see 25 words (initially) and need to guess which ones the spymaster is hinting should be guessed. By using the closest words to reporter one can find a word that is "close" to the team's words and "far" from the words of the other team or the codeword of the assassin.
Here is a program that partially implements a spymaster. Given a list of words it finds the best clue for two of those words. Starting with this program you can make a program for playing Codenames. Try enhancing it to search for clues for more than two words at a time. Enhance it to make sure that none of the possible clues suggest the other team's codenames or the assassin's codename.
Word and sentence embeddings can be used as a component in AI programs that do sentiment analysis, entity detection, recommendations, summarizing text, translation, and question answering. This is typically done by replacing the words or phrases in a text with their embeddings and then training a machine learning system on these approximate meaning of the words. This makes the systems work better with synonyms and paraphrasings.
Word embeddings are learned by examining text with billions of words. These texts may have captured societal biases. For example, the following example seems to have captured the bias that butchers are male and bakers are female. But the bias is so weak that if cosine similarity is used instead of Euclidean distance the unbiased "chef" is found. Some word embedding databases have the bias that doctors are male and nurses are female. They will answer the question "man is to doctor as woman is to X" with "nurse". Is this a bias? Or might it be due to the fact that only women can nurse babies? Run some experiments below to explore these kinds of questions.
A paper called Semantics derived automatically from language corpora contain human-like biases proposed a way to measure word biases. The idea is to use the average distance two words have to two sets of "attribute" words. To explore gender bias, for example, the attribute word lists can be "male, man, boy" and "female, woman, girl". The difference of the average distances provides a score that can be used to compare words. In this implementation of the scoring reporter one can see that "mathematics" has a higher "maleness" score than "art". And "art" has a higher "pleasantness" score than "mathematics".
While we don't really know what the numbers mean, they must be encoding lots of things about words such as gender, grammatical category, family relationships, and hundreds more things. But the numbers aren't perfect. See if you can create some examples where the results are not good. One known problem with how the numbers are generated is that it combines features of different senses of the same word. There is only one entry, for example, for 'bank' which combines the ways that word is used in sentences about financial institutions and those about the sides of rivers. This can cause words to be closer than they should be. For example, "rat" and "screen" end up being closer together than otherwise due to "rat" being close to "mouse" and "mouse" (the computer input device) being close to (computer) "screen". This is a problem researchers are working on. Another problem is that sometimes short phrases act like words. "Ice cream", for example, has no word embedding while "sherbet" and "sorbet" do.
Here is a program that asks the user for two languages, obtains the feature vector of a random word from the first language, and then displays several of the words closest to that feature vector. It places the words in the t-SNE two-dimensional approximation of where the 300-dimensional words really are.
The word embeddings for each language were generated independently based upon text from Wikipedia and the web. The location in 300-dimensional space of the features for a word like 'dog' have no relationship to the location of features of translations of the word 'dog'. Researchers noticed that in most (all?) languages some words are close together. For example, 'dog', 'dogs', puppy', and 'canine' are close. Words like 'wolf', 'cow', and 'mouse' are close but not as close as those words. And all of these words are far from abstract words like 'truth' and 'logic'. So they discovered that it is possible to find a rotation that will cause many word embeddings in one language to be close to corresponding words in another language. The way it was done at first and in these Snap! blocks is by giving a program a word list between English and each other language. 500 words is enough to find a good rotation that brings most of the other 19500 words close to where their translations are. While it is impressive that translation works at all given a word list that covers only 2.5% of the vocabulary, Researchers at Facebook describe a technique that uses no word lists or translated texts. A rotation is all that is needed because all the word embeddings are centered around zero so they don't need to be translated (in the mathematical sense, i.e. moved) as well. But note that the translation happens in 299 dimensions!

In the figure (A) and (B) show X being rotated to match Y to make a small number of words in X align with their translation in Y. Many other words become roughly aligned as a result. Other techniques can be applied to improve the alignment.
Using a similar technique to how vectors are generated for words we can also generate vectors for images. The get costume features of ... block will pass a vector of 1280 numbers to the blocks provided. This uses MobileNet to compute the numbers from the "top" of the neural net.
One can use image embeddings to determine which images are close to other images. Closeness takes into account many factors including texture, color, parts, and semantics. Image embeddings can be used to work out image analogy problems similar to how word analogy problems are solved.
In the machine learning chapter there is a description of the train with image buckets ... block which is used for training. It works by collecting the feature vectors of all the training images and then finds the nearest neighbors to a test image to determine what label to give the image.
Here are some project ideas:
New word embeddings blocks could be added. Currently the word embeddings blocks excludes all proper nouns. If we added them one could solve analogies such as Paris is to France as Berlin is to X. Exploring how words change over time can lead to great projects. Word embeddings generated from publications in different time periods could be used to see how words like "awful" and "broadcast" have changed over the last two centuries. New blocks could be added based upon research on generating "word sense" embeddings instead of word embeddings. E.g., one sense of "duck" is close to "chicken" while another sense is close to "jump".
There is plenty more that AI programs can do with language including determining the grammatical structure of sentences (this is called "parsing"), figuring out the sentiment in some text, and summarizing text. We plan to add more.
Wikipedia's word embedding article is short and written for an advanced audience. The Facebook team wrote a paper detailing how they generated the word embeddings we used here: E. Grave, P. Bojanowski, P. Gupta, A. Joulin, T. Mikolov, Learning Word Vectors for 157 Languages. The Understanding word vectors web page has a very good introduction to the subject and the contains examples that are helpful but require familiarity with Python. This Google blog about biases in word embeddings is very good and clear. Google's Steering the right course for AI discusses bias along with other societal issues including interpretivity, jobs, and doing good. Fair is Better than Sensational: Man is to Doctor as Woman is to Doctor discusses biases in word embeddings in depth. How to Use t-SNE Effectively is a clear interactive description of how t-SNE works. Exploiting Similarities among Languages for Machine Translation pioneered the idea adjusting the word embeddings to support translation. Word Translation Without Parallel Data explores how word embeddings can be used for translation without using word lists or translated texts. projector.tensorflow.org is a great website for interactively exploring different ways of visualizing high-dimensional spaces. Here is a video of a nice talk by Laurens van der Maaten who invented the idea of t-SNE.
You can import the blocks presented here as a project or download them as a library to import into your projects.
Go to the next chapter on neural nets
Return to the previous chapter on machine learning.